Github is a double edged sword. Use it when you must, but you should self-host whenever possible.
I started with gitlab as it was the most popular github alternative at the time, and I think for medium-large businesses hosting their own local, dedicated git instance, gitlab is probably a good choice.
For me though, gitlab wad definitely overkill. The upgrades get very complicated, and I'm ultimately just not a big Ruby on Rails fan... I just wanted locally hosted git that I could also browse easily via http, especially to graphically view older commits and branches, because every once in a while I do leave the terminal...
After gitlab my next solution was Gitea, as I read it was a community fork of gogs so I assumed it must be better... In hindsight, I would say Gitea is working hard to compete with GitLab. That's fine, but `GitLab` is actually what I wanted to get away from.
Here's an old sysadmin rule of thumb: If it involves LDAP, run the other way!
Me, screaming... every time I do something with LDAP...
In all fairness, LDAP is necessary for directory based authorization and authentication. With lots of users, you're kind of stuck with it and so you better know how it works. Everything connected to X.509 is a whole different mindset than the rest of the Linux and Open Source movement. If software had an attitude, ldap software and the zshell would be at opposite edges of the attitude spectrum.
I spent a long time actually getting gitea to work in my particular configuration, and just ended up dedicating way more time to it than I really wanted to. For me, git isn't very much different from samba... I just want it to work so I can focus on problems that I'm more interested in.
I would recommend gitea to anyone looking at gitlab and vice versa. These two are very similar. I think that blindly running either of them in a container just because you can is asking for trouble though. Go through the manual instillation and know how to set things up from scratch. If you can't do that, you shouldn't run it, because you won't be able to fix it when things go wrong. You want a sysadmin that knows how to set these up and how to manage them, back them up, and fix problems along the way.
So I spent far more hours than I'm proud to admit trying to get gitea working in my particular environment, but when I decided to switch over to gogs, I had it all working and my old repos migrated over within 30 minutes.
If you're just looking for a simple, self hosted git server via `https` in 2022, I think that gogs is what you are looking for.
Another nice "self hosted" option is cgit but the default interface is very dated, and it's even more minimal than my ideal feature set.
If neither gitlab, gitea, gogs or cgit are what you're looking for, maybe check out the awesome self hosted list, but a lot of these are very niche and not well supported.
OpenSSH Server on Windows is very cool, and very weird...
You need to open a PowerShell Prompt as Administrator
If you're going to connect to Windows via OpenSSH, I think you're really best off using PowerShell rather than cmd.exe, as PowerShell can do quite a bit more from the command line that's impossible with cmd.exe.
# Install the OpenSSH Server
Add-WindowsCapability -Online -Name OpenSSH.Server
# Start the SSH server
Start-Service sshd
# or the even shorter and older...
net start sshd
32-bit versions of windows shipped with a ported version of edit.exe from DOS that would work in a command prompt. The 64-bit editor that works in every version of windows and is guaranteed to be installed is notepad.exe. Obviously that's not going to get us very far via ssh so we need a way to edit in the terminal.
The best solution is to install neovim via scoop. If you're not into neovim, regular vim or nano (doesn't use vi keys) would also work.
# Allow PowerShell to run RemoteSigned code
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
# Install scoop
iwr -useb get.scoop.sh | iex
# Install git - required for scoop to operate
scoop install git
# Install neovim
scoop install neovim
# or `scoop install vim` if Lua is too fast for you
# or `scoop install nano` if hklj are too powerful...
# Install the VC++ runtime (recommended for neovim)
scoop install vcredist2015
Most regular *nix machines put the sshd configuration in /etc/ssh/sshd_config. For Windows, the /etc/ssh directory is: C:\ProgramData\ssh. Inside of this directory you'll see:
The point is that in a multi-admin environment, you'll realistically want every admin to at least have their own home folder, and not effectively be sharing a login... Using Microsoft's default, the username is set by user set in the ssh user@server command.
If you use any path under ProgramData for your keys, you'll need to icalcls to set exactly these permissions, of course update your file name accordingly.
In my case, I'm just running this as a virtual machine for development, so I just commented out the #match group Administrators Authorized Key File which simplifies permissions and behaves more like you expect of ssh. In a real server environment, I would definitely go with: PROGRAMDATA__/ssh/%u/authorized_keys
#Match Group administrators
# AuthorizedKeysFile __PROGRAMDATA__/ssh/administrators_authorized_keys
Last, you need to add your ~/.ssh/some_key.pub public key to the authorized_keys file that you've chosen, and then restart sshd.
net stop sshd
net start sshd
Now you should be able to log in via:
ssh myuser@windows-host -p 22 -i ~/.ssh/some_key
Once you've got SSH connected, I would recommend setting ssh to launch powershell as the default shell rather than cmd, so that you can edit the registry via SSH.
New-ItemProperty -Path "HKLM:\SOFTWARE\OpenSSH" -Name DefaultShell -Value "C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe" -PropertyType String -Force
# Check that it's set with:
Get-Item -Path "HKLM:\SOFTWARE\OpenSSH"
You can list the current version of windows that's being used via cmd.exe's 'ver' shell builtin.
cmd.exe /c ver
# Windows "11" is:
Microsoft Windows [Version 10.0.22000.318]
Windows 11 ships with WSLg allowing display of GUI apps, supporting both Wayland and X11 APIs...
If you've been using a terminal for a while, you've surely stumbled across the terminal's legacy keyboard handling. Terminal escape codes were created in the 1970s and haven't been updated much.
CTRL + J == newline
CTRL + I == tab
These two examples are some of the least annoying, but the implications aren't at first obvious. Normal terminal apps can't tell whether you actually typed "ENTER" on your keyboard or "CTRL" + "I". From the perspective of the app, it's the same. Sadly, that's just the tip of the iceberg for these limitations.
CTRL + ... Sequences starting with CTRL+... are basically used up by the way the terminal represents common data (CTRL + D == EOF) with "CTRL CODES", and CTRL+SHIFT+letter is the same as CTRL+letter
SHIFT + ... The terminal doesn't know the difference between "Shift + s" and "S"...
Hyper +... Hardly any apps are cool enough to be able to work with the awesome hyper modifier... Without an enhanced way to process keycodes, this isn't possible.
Many terminals rely on timing to distinguish codes like Alt+C from Esc + C... This generates lag and errors when typed too slow or too fast. vim-fixkey has a nice list of workarounds to get full access to keypresses in the terminal, though even in the best case scenario, it would be limited by a timeout, and not work for Cmd, Hyper or various CTRL+x keys...
Some of this is "worked around" with the XTerm ModifyOtherKeys option that's also supported in gnome-terminal and Konsole. Unfortunately ModifyOtherKeys is not complete.
There is discussion on the NeoVim github issues about adding fixterms support in neovim, but at this time (Nov 2021) it seems that no support is yet complete. It looks like neovim/src/nvim/keymap.c probably holds most of the code that needs to change.
Someone may have worked on an actual code change for this, tracking at: https://github.com/neovim/neovim/issues/6279
TUI: enable/disable modifyOtherKeys automatically https://github.com/neovim/neovim/issues/15352 TUI: distinguish Tab, CTRL-i (S8C1T mode) https://github.com/neovim/neovim/issues/5916 CTRL-Alt-Space isn't recognized even though terminal sends ^[^@, works in Vim https://github.com/neovim/neovim/issues/14836
See: "xterm-8-bit" Nvim does not use 8-bit sequence detection, and always uses 7-bit sequences (for now)
One day, hopefully Neovim will support these sequences by default, but in the mean time it's possible to map these sequences manually in Kitty and Neovim, it's possible to manually use a specific mapping by configuring Kitty's map ... send_text
\x 1b [ 9 ;5u
\x 1b [ 9 ;6u
^ 1b = 11011binary == turn on Disambiguate Esc Codes, Report Event Types, Report All Keys as Escaped, Report Associated Text
[ is just the end of our escape code
9 is the keycode for Tab
5u = 1 (constant) + 4 (0100) Control
6u = 1 (cont) + 5
4 = ctrl + 1 shift = 5
Let's go through a few more examples. Let's try: CTRL + Super + Tab. Unfortunately, even though Kitty can send this one, until Neovim's keyboard support is more complete, it doesn't look like Neovim has any way to receive this keycode.
If you haven't tried the kitty terminal emulator, it's an awesome one. Even if I was still tortured to use Mac OS X, I think I would use Kitty of iTerm. You'll find that it's noticeably faster than gnome-terminal or vscode's built in terminal. (konsole is pretty snappy though)
Kitty has tons of features, however the process to discover and configure those features is a bit more complicated than other terminals that I've used.
For me, the most confusing aspect of kitty was understanding how to setup fonts. I never wanted to learn how kitty deals with fonts. I just wanted a kitty font config that works. If that's all you want, skip to kitty config.
First, Kitty requires that fonts have a fixed spacing of 100 defined. To check if a font can be used by Kitty, and the exact name you should enter to configure it, you'll want to use:
kitty list-fonts
If you're looking for a good font to use, I suggest you take a look at the open source Fira Code font, since it has nice ligatures for programming...
Fira Code example "ligatures" o visually simplify display of == --> ++ and :=
If you you have a budget to invest in a programming font, I think the MonoLisa font is even more attractive. To get a monospaced font to show up in Kitty if it's not showing up on it's own, you'll need to edit ~/.config/fontconfig/fonts.conf and add a section to "scan" for the font "family" and set "spacing" for that family to 100.
Once you edit fontconfig/fonts.conf you'll need to rebuild the font cache and restart kitty to see the new font.
sudo fc-cache -fr
If kitty list-fonts still can't find the font that you're looking for, several steps possible steps to resolve are discussed on the kitty issue tracker.
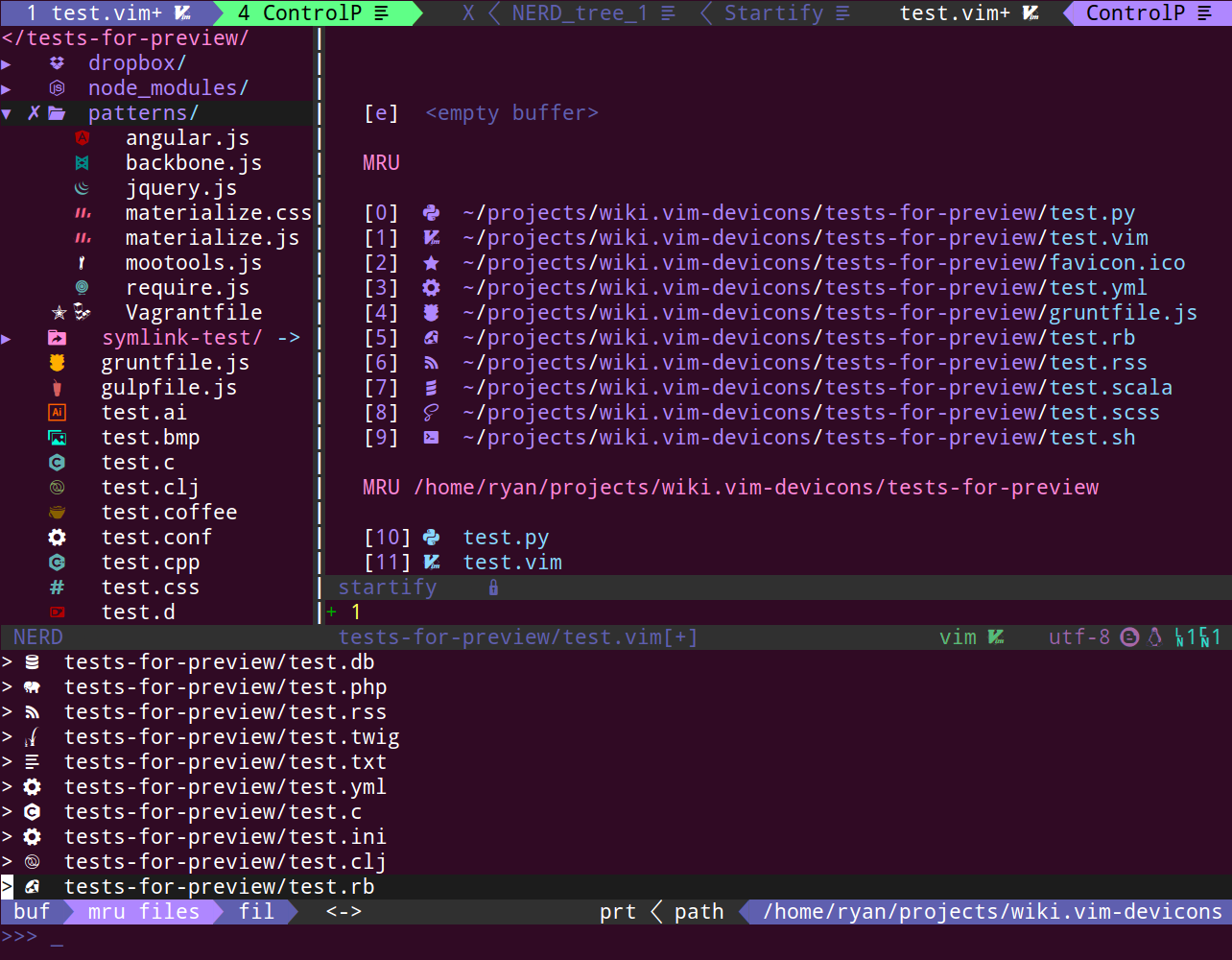
Most terminals need you to setup "patched fonts" if you want to use "powerline" symbols... If you're looking to rice your command line, powerlevel10k, vim-devicons, and vim-airline can will use many of these "patched font" symbols.
vim-airline using patched fonts...powerlevel10k zsh theme using patched fontsvim-devicons with patched fonts
If you want to use the "fontconfig" method for your whole configuration, you might be able to add something like the following ~/.config/fontconfig/fonts.conf so that symbols from the Symbols Nerd Font will be preferred, but I was not able to get this method to work, so I went with the kitty symbol_map method.
<alias>
<family>monospace</family>
<prefer>
<family>MonoLisa</family>
<family>Symbols Nerd Font</family>
<family>Noto Color Emoji</family>
<family>Noto Sans Symbols2</family>
</prefer>
</alias>
Yes, you list all of them them [symbol_map] and yes you can have multiple ones. However, I recommend against doing that, there is rarely a need for it, since nerd fonts will automatically be used if found in most cases.
kovidgoyal, author of kitty
For me though, "auto detection" of nerd fonts never worked. The most evident example was each time I would run:
vim ~/.vimrc
The stylized "V" from vim-devicons would show a very rarely used Chinese character...
Editing .vimrc, the stylized V is shown for me as: 金 + 弦, which doesn't exist in most chinese dictionaries... Editing .vimrc, the correct stylized "V" icon from vim-devicons
The "quick and dirty" way to get every symbol you want to load is the use the patched Nerd fonts, for example the Fira_Code_vX.X.zip patched Nerd Fonts.
However, with Kitty, the preferred way to get each font to show up is actually NOT to use patched fonts, instead to use kitty's "symbol_map" function.
Map the specified unicode codepoints to a particular font. Useful if you need special rendering for some symbols, such as for Powerline. Avoids the need for patched fonts. Each unicode code point is specified in the form U+<code point in hexadecimal>. You can specify multiple code points, separated by commas and ranges separated by hyphens. symbol_map itself can be specified multiple times. Syntax is:
symbol_map U+E0A0-U+E0A3,U+E0C0-U+E0C7 PowerlineSymbols symbol_map codepoints Font Family Name
If you run kitty with, you'll get a list of each character code that's not found on the terminal you launched kitty from.
kitty --debug-font-fallback
For example, on the Right I'm using xterm to edit ~/.config/kitty/kitty.conf and on the left is my kitty instance... Here you can see pretty clearly the "DejaVu Sans Mono" font is providing the U+2605 (★) and U+21b6 (↶)
I would prefer to get all of the Nerd Fonts from the Nerd Fonts package.
First, make sure you download the "Symbols Nerd Font" (symbols only) font package, you can find it at:
Once you have the Symbols-2048-em Nerd Font Complete.ttf, copy it to ~/.local/share/fonts and then run sudo fc-cache -fr to reload the font cache.
Next, you'll want to add something like this to your kitty config:
font_family FiraCode
# or #
font_family MonoLisa
###########################################################
# Symbols Nerd Font complete symbol_map
# easily troubleshoot missing/incorrect characters with:
# kitty --debug-font-fallback
###########################################################
# "Nerd Fonts - Pomicons"
symbol_map U+E000-U+E00D Symbols Nerd Font
# "Nerd Fonts - Powerline"
symbol_map U+e0a0-U+e0a2,U+e0b0-U+e0b3 Symbols Nerd Font
# "Nerd Fonts - Powerline Extra"
symbol_map U+e0a3-U+e0a3,U+e0b4-U+e0c8,U+e0cc-U+e0d2,U+e0d4-U+e0d4 Symbols Nerd Font
# "Nerd Fonts - Symbols original"
symbol_map U+e5fa-U+e62b Symbols Nerd Font
# "Nerd Fonts - Devicons"
symbol_map U+e700-U+e7c5 Symbols Nerd Font
# "Nerd Fonts - Font awesome"
symbol_map U+f000-U+f2e0 Symbols Nerd Font
# "Nerd Fonts - Font awesome extension"
symbol_map U+e200-U+e2a9 Symbols Nerd Font
# "Nerd Fonts - Octicons"
symbol_map U+f400-U+f4a8,U+2665-U+2665,U+26A1-U+26A1,U+f27c-U+f27c Symbols Nerd Font
# "Nerd Fonts - Font Linux"
symbol_map U+F300-U+F313 Symbols Nerd Font
# Nerd Fonts - Font Power Symbols"
symbol_map U+23fb-U+23fe,U+2b58-U+2b58 Symbols Nerd Font
# "Nerd Fonts - Material Design Icons"
symbol_map U+f500-U+fd46 Symbols Nerd Font
# "Nerd Fonts - Weather Icons"
symbol_map U+e300-U+e3eb Symbols Nerd Font
# Misc Code Point Fixes
symbol_map U+21B5,U+25B8,U+2605,U+2630,U+2632,U+2714,U+E0A3,U+E615,U+E62B Symbols Nerd Font
The list of code point ranges above comes directly from the nerd-fonts test script, with the exception of the "Misc Code Point Fixes" that I added myself through trial and error with --debug-font-fallback.
You can test that you've got all fonts configured properly by running the "test-fonts.sh" script provided by nerd-fonts.
Be sure to run kitty with kitty --debug-font-fallback then run this script in your kitty window, and if you've set everything up correctly, you should not see any of the symbol missing or symbol fallback notices that were shown in the screenshot above. Once properly configured you'll get:
Note that there may still be a few messages, but generally all characters will now load correctly.Small excerpt of the "test-fonts.sh" script once kitty is properly configured
If you're experimenting with MonoLisa, here are some settings that I found looked great.
Without the "adjust_baseline -4", the MonoLisa font was not aligned when I tried.
One last nugget of wisdom here, the "codepoints.net" site is the best unicode character lookup site I've ever seen. You can type the codepoint directly in the URL, and the layout is clean and free of ads.
https://codepoints.net/U+21B5
Did you know there are Unicode codepoints for Egyptian Hieroglyphs? Now you can put heiroglyphs in your terminal!"
Egyptian Hieroglyphs in markdown document displayed via kitty terminal
Firefox used to have some plugins that you could use to customize your command keys pretty easily, but as Firefox has evolved recently, many of the XUL generation of shortcut keys has been disabled.
It's very easy to rebuild Firefox to support the keys that you want though. First, you'll want to run once to build the initial "key-shortcuts.properties" file.
Open key-shortcuts.properties, you'll find it in: Then you'll want to change the default C shortcut key that conflicts with my terminal muscle memory of CTRL+C to interrupt, and Shift + Ctrl + C as Copy...
# LOCALIZATION NOTE (inspector.commandkey):
# Key pressed to open a toolbox with the inspector panel selected
inspector.commandkey=M
The full workflow is...
# Grab the friendly mozilla build bootstrapper
cd ~/SourceInstall
curl https://hg.mozilla.org/mozilla-central/raw-file/default/python/mozboot/bin/bootstrap.py -O
# Run the bootstrap script
python3 bootstrap.py
# Do a test build to make sure it works
./mach build
./mach run
# edit file you want to change
./mach build
./mach run
# test your shortcut now works...
cd ~/SourceInstall/mozilla-unified/obj-x86_64-pc-linux-gnu/dist/bin
# or link to anywhere else in your path that
# will have higher precedence than /usr/bin
sudo ln -s $HOME/SourceInstall/mozilla-unified/obj-x86_64-pc-linux-gnu/dist/bin/firefox /usr/local/bin/firefox
Enjoy beginning to really customize Firefox... Hopefully for you this is the beginning of more meaningful Firefox hacking than just editing a config file.
If your on Linux, you'll be unpleasantly surprised to find this MSDOS classic has been wrapped up in a Windows installer that requires DotNet45 (AKA Mono), and tries to cram a bunch of spyware onto your system.
apt install wine winetricks
winetricks dotnet45
wine Turbo\ C++ 3.2.2.0.exe
Once the installer is done, you'll have "Turbo C++.zip" in your Wine/Window Downloads folder
This .zip file is what you've really been after... Extract this to wherever your mapping your dosbox C: drive... For me, that's: ~/dosbox
You'll probably want to do some dosbox configuration, so you can give it more of a 1995 feel...
vim $(dosbox -printconf)
[sdl]
windowresolution=1280x960
output=opengl
[autoexec]
@echo off
mount c ~/dosbox
PATH %PATH%;C:\TURBOC3\BIN;C:\VIM\VIM70;
C:
Once that's all done, just type dosbox to open your new strangely oversized DOS window, then type tc to open the IDE...
You have syntax highlighting and a small set of libraries available...
Borland Turbo C++ 3.0, released 1992
To Install MASM (Microsoft Assembler) you'll need to virtually mount floppy disks...
mount a: ~/dosbox/masm611/floppy -t floppy
Fortunately, dosbox doesn't do any validation on the floppy maximum size... In the MASM installer, if you copy each of the disks (DISK1, DISK2... DISK5) into one folder and then mount that folder as one floppy... The MASM installer will install all of the files with no complaint.
Actually using a 16-bit system for a few hours and it's quite amazing how far we've come, especially Linux... Version 0.02 of Linux started when MASM for DOS and Borland Turbo C++ were still shipping. Initially Linux with gcc v1.40 on top of Minix.
Minix was written for use in teaching operating system concepts. Would be a lot of fun to go through development from a kernel to a booting system.
The Good Old DOS Days we're really the bad old days in terms of how software and the development environment worked... I would be very surprised if many people used to Linux in 2021 could write anything in Turbo C++ for Dos that was generally useful today... Not impossible to do, but just the very long way around...
Gnome is a trailblazer. Desktop icons? Using the Win/Cmd/Super key as a shortcut key? Getting rid of backwards compatibility? The Gnome developers are always eager to try new things...
There was once a time when the KDE (kwin) folks and the GNOME (mutter) folks appeared to get along quite well, and jointly created several versions of the wm-spec of the FreeDesktop.org Specifications. Collectively, the FreeDesktop specifications are why application developers can create apps that work across various types of Linux desktops.
Many parts of the spec are frequently updated, but sadly the wm-spec portion of the FreeDesktop.org specifications hasn't gotten gotten an update since November, 29th 2011.
The wm-spec defines "Extended Window Manager Hints". Messages that applications, window managers, pagers (navigation aids like virtual desktop selectors), and automation applications such as xdotool and wmctrl.
The wl-roots project that provides the foundation for SwayWM, basically the Wayland port of the i3 tiling window manager, may eventually become a sort of successor to wm-spec, giving other desktops a common platform to build for Wayland on top of, however, I don't think GNOME or KDE are building on top of wl-roots. The future best case scenario may be code that works for wl-roots, KDE and GNOME... So for anyone that thought using xcb, the C interface directly to the X11 protocol, was difficult, there's not even a consistent layer to write to once everything moves to Wayland. Hopefully Arcan or something else comes out and surprises us, as I think Wayland could be a significant step backwards for the most sophisticated users. That said, the WL-ROOTS author seems to be optimistic on Wayland...
X11 has been updated periodically since it's initial release in 1987. Lots of things change over the years... The MOTIF_ related proprieties aren't used very often any more.
You can read all of the properties for any window you're interested in with xprop. For example:
# use -len 80 to drop X11's archaic icon info
xprop -len 80
Prior to _GTK_FRAME_EXTENTS, the next most recent window sizing method was to check _NET_FRAME_EXTENTS.
_NET_FRAME_EXTENTS,
left, right, top, bottom, CARDINAL[4]/32
The Window Manager MUST set _NET_FRAME_EXTENTS to the extents of the window's frame. left, right, top and bottom are widths of the respective borders added by the Window Manager
GNOME released a new property called _GTK_FRAME_EXTENTS that usually have a value close to 25, 25, 25, 25... In 20202, KDE's KWin window manager was updated to automatically handle _GTK_FRAME_EXTENTS, so if you're a user or developer who's trying to understand how this property works on Kwin, it's even more confusing, because Kwin takes these values into account, and then gets them out of your way. This is the ideal behavior. Congratulations to the Kwin team. However, don't expect to understand this property if you're using a version of Kwin that already effectively hides it.
I had been searching for documentation on how exactly `_GTK_FRAME_EXTENTS` worked for a few weeks, but on KDE I just couldn't make any sense of it. I even found this video and though "isn't that just doing what it was supposed to do? what did it look like before?"
Today when I was using Gnome for a while, it finally all came together.
# &! to launch and disconnect from the terminal
gnome-calculator &!
kcalc &!
# give your windows a moment to open
sleep 1
# -x to use a window class, not window title
# 100,100 should now be top left of window (X,Y)
# 300,300 is less than window minimum, ignored
wmctrl -x -r "gnome-Calculator" -e 0,100,100,300,300
wmctrl -x -r "kcalc" -e 0,100,100,300,300
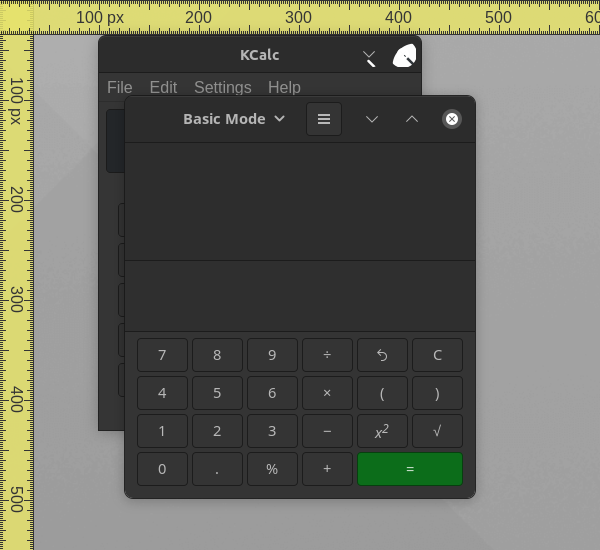
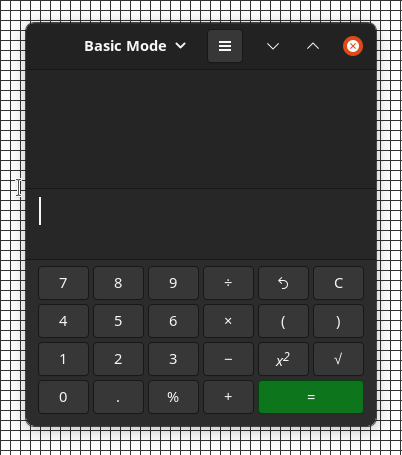
Ideally, these two windows would now be in the same X, Y position... Just looking at this image (taken on Gnome on X11) and you can probably figure out how _GTK_FRAME_EXTENTS works.
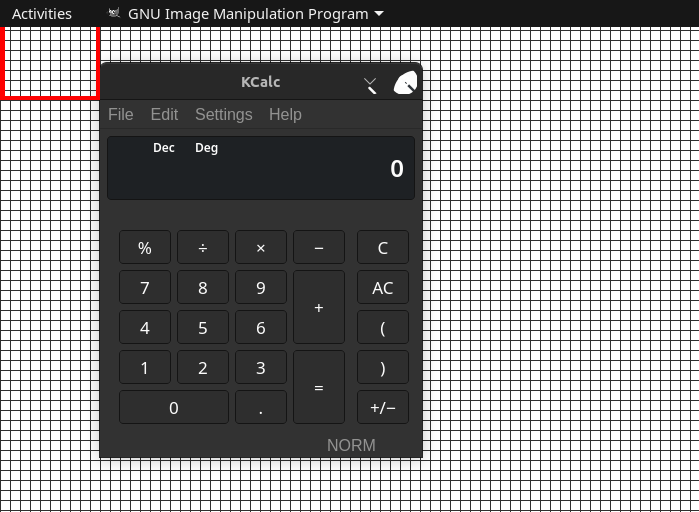
Here's a screenshot of gnome-calculator with a 10x10 pixel grid in the background...
And when we run xprop on this gnome-calculator window, we get:
_GTK_FRAME_EXTENTS(CARDINAL) = 26, 26, 23, 29
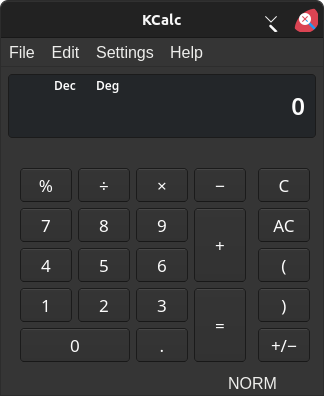
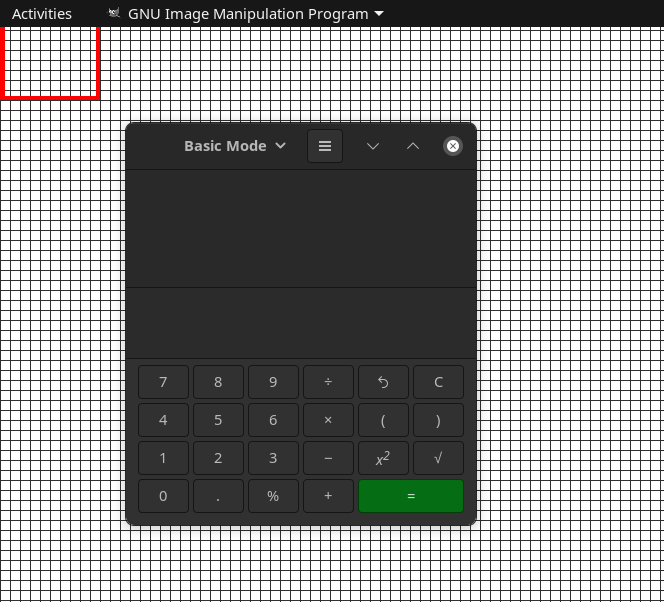
Just to make sure that we don't have any ambiguity, let's try the same thing on kcalc and see what we get.
_NET_FRAME_EXTENTS(CARDINAL) = 0, 0, 37, 0
🎠Putting a bow on it...
So GTK creates a large buffer around the edges of every window. I presume this could be used for dropshadows and other eyecandy. As a result, window is actually much larger than you expect the window to be. The _GTK_FRAME_EXTENTS values (Left, Right, Top, Bottom) communicate how much of the window should be cropped off when considering things like window "snap to edges".
Meanwhile the KDE Kcalc window is using _NET_FRAME_EXTENTS (Left, Right, Top, Bottom), and the actual Window that you would use for placement and alignment extends that much BEYOND the size of the window.
_NET_FRAME_EXTENTS tell you how much EXTRA SPACE add to your Window Size calculations.
_GTK_FRAME_EXTENTS tell you how much EXTRA SPACE to REMOVE from your Window Size calculations.
Here I wrote a Xlib program that just displays a 3pixel, red frame window in the top left, starting at point 0,0. It's 100 x 100 pixels.
You can see, the top left of the Kcalc window (x=100, y=100) is just inside of the titlebar.
Meanwhile, the top left of the of the Gnome-Calculator window using _GTK_FRAME_EXTENTS is actually fully outside of the GTK window..
_GTK_FRAME_EXTENTS should work the same on Wayland, but xprop and wmctrl surely will not since they're directly based on X11.
Hopefully Wayland will soon have command line tools like wmctrl and xdotool and hotkey tools like sxhkd that can work on any Linux or BSD desktop environment on top of Wayland...
So be sure when you step, Step with care and great tact. And remember that life's A Great Balancing Act.
Theodor Seuss Geisel
Security, like the rest of life, is a great balancing act. A rock on the bottom of the ocean is about the most secure thing in the world, but it's not terribly useful... There are always tradeoffs.
Generally, FTP should be avoided, because with normal FTP your passwords will be sent over the wire in plaintext and vulnerable to replay attacks. All of your data will also be sent over the wire in plaintext, so adiós to any sense of confidentiality for the data you sent that way. There are still times with FTP makes sense to use though, most especially over very lossy, high latency networks, when transferring content that is already public, like static website resources. If you're forced to use FTP, and you will do so repeatedly, make sure to choose a client and server that at least encrypt the authentication.
On any network connection that isn't the equivalent of institutional Grade D beef, you should be using SFTP (SSH File Transfer Protocol) or FTPS (FTP over TLS/SSL).
Sometimes you have a single User Account that you want to share with multiple devices. For example, maybe you want your Tablet to connect to SFTP to your Linux box, but you don't want that key to have full shell access.
Sometimes you should use the "full solution" of creating a separate user account, giving that user a locked down, perhaps chrooted shell, but then you need to figure out the user/group permissions of the files in question, how to maintain those permissions over time, and whether those permissions changes will be compatible with the rest of the required workflow.
There's a little used, not widely understood feature of SSH's ~/.ssh/authorized_keys file, you can prefix each key with:
Most Android "SFTP File Transfer" interfaces like Solid Explorer or the Fx File Manager use /usr/lib/openssh/sftp-server to get the SFTP transfer started, while most command line users will use scp or rsync to move files around.
This can be a nice in-between solution. Far better than sharing an SSH key between multiple devices (because you can easily remove it if any device/user is now gone, accountability, etc) but also a far simpler solution than a whole new account.
It ultimately depends on what you're doing.
You could even experiment with doing a chroot in this script to further tie things down, though keep in mind the chroot environment usually needs several things mounted for kernel access.
If you have any problems getting this setup, just turn on debugging on your SSHD server, and watch the log on your SSHD server, and you should be able to figure it out if you read carefully.
# /etc/ssh/sshd_config
# Change LogLevel
LogLevel DEBUG
# Save and Quit
systemctl reload ssh
On Debian, the SSHD logs will be under:
/var/log/auth.log
On RHEL the's are /var/log/secure
If it's neither of those, you might be stuck using journalctl to access the sshd logs.
If you turned on DEBUG level logging, don't forget to turn it back off.
Yet I've never found exactly where/how either of these tags are generated... Perhaps it just never got my attention enough. Well, all of that changes now.
The rcs (GNU RCS revision control system) first released in 1991, includes a command called ident. The ident command manual page starts:
NAME
ident - identify RCS keyword strings in files
SYNOPSIS
ident [ -q ] [ -V ] [ file ... ]
DESCRIPTION
ident searches for all instances of the pattern $keyword: text $ in the named files or, if no files are named,
the standard input.
Not many people use rcs these days, but it's also possible to do this with other version managers. The key is to know that a "$...$" string is called an "Ident String".
Note that before 2020, the default capability of "$ident$" strings in git was quite limited. Fortunately, "filters" have been extended to provide a lot more information, so you should be replicate ident in git now.
I started my tech life working with FoxPro and the BASIC language... I wrote in SuperBase, Visual Basic, Perl, Ruby and Shell Scripts. All very high level languages. I always wanted to learn what was truly happening inside of the machine, but I was either too intimidated or too busy to learn low level languages. I moved into management, sales and business, and would code a bit over the years, but I had become a generalist.
A few years back I started getting back into writing software again. I looked at Perl 6. That's interesting, but why? I looked at some of the newer JavaScript and TypeScript, but none of it satisfied my curiosity. I wanted to know what's really going on. Something lower level and faster!
I started writing a fair amount of Go. It's a pretty nice language. Very easy. If I were writing a large app with several developers, I think Go may be a good choice. Everything is simple, compact, and standard. The more I got deeper into Go, the more I would see that I still didn't understand what's happening in the machine. I was reading something like "Advanced Go" that was talking about how to connect Go to C and I though, why am I doing this instead of just writing in C?
I had written a little bit of C in school, but never got very good at it. At that time, the money I could make solving other people's problems in high level languages was more interesting to me than understanding what was actually happening inside the machine.
Head First C - Chinese Edition... I actually read the English version, though this one might be more fun
I found a great C book... Head First C. I wish my college had used this as the C textbook instead of the dry, sleep inducing tome the professors chose. I started writing C and enjoying it, but I had a lot of problems solving some of the memory errors, especially at first. You could say that I hit these problems because I didn't have very much experience in C. I would say I hit them because I had finally gotten closer to the processor, but I still didn't know what's going on.
So I thought to myself, a simple C introduction wasn't difficult at all. It was fun and enjoyable. What if there's something similar for Assembler?
Assembly Language Step-By-Step
So I found Assembly Language: Step-By-Step. The author's idea is to teach Assembly Language as a first programming language. It's an interesting idea.
Anyway...
The blog post title... How fast is Assembly, and how slow are Go and C? The thing to remember with ASM is that each line of your assembly code corresponds to object code that you'll feed the processor.
SECTION .data ; init data
HelloMsg: db "Hello world!",10 ;
HelloLen: equ $-HelloMsg ;
SECTION .text ; code section
global _start ; link needs this to find the entry point
_start:
mov eax, 4 ; sys_write syscall
mov ebx, 1 ; stdout (file 1)
mov ecx,HelloMsg ; pass offset of message
mov edx,HelloLen ; pass length of message
int 80H ; syscall
mov eax, 1 ; exit syscall
mov ebx, 0 ; return 0
int 80H ; syscall
Assuming code is in a file named asm-hello.asm, run the following to build and test (assuming you're on a 64 bit machine)
If you've never written assembler before, and you're not quite sure what any of that means... eaxebxecx and edx are registers. You trigger the syscall with interrupt 80H (code 128). If you want a better explanation of how and why it works, read the book linked above.
Performance Testing with perf
The interesting thing about this, is that I don't think you could make a hello world program significantly shorter.
sudo perf stat -r 1000 -d ./asm-hello
For this tiny asm example, you can see it took 0.00029 seconds to execute.
Total execution time: 0.000296 seconds
For the C version, I set -Ofast for maximum optimization. On such a simple program I don't think the optimization made any difference.
C version with -Ofast, Total execution time: 0.000498 secondsGo version, Total execution time: 0.000984 secondsPerl version, Total execution time: 0.00135
Of course it's very possible that you could write awful ASM and either never get it to work or get it to work so bad that it's even slower than any of the other options. It's just interesting to see how much different the speed can be. If you do have a part of a Go program that's too slow, it makes a lot of sense to move that part to C. If you have part of a C program that's too slow, it makes a lot of sense to move that part to ASM.
This clarifies for my why old programs on old hardware were so fast! Because RAM and CPU were both extremely expensive, lots of things were written in ASM.
Now that RAM and CPU prices are so low, most RAM segments and CPU cycles are thrown away on things likeElectron...